The LinkedIn algorithm in 2025 has undergone significant updates aimed at enhancing user experience and content visibility. Here are the key features and changes:
Core Principles of the Algorithm
Relevance: The algorithm prioritizes content that aligns with users’ professional interests and relationships, ensuring that the most pertinent posts appear first in their feeds14.
Engagement: Content that generates high engagement—through likes, comments, and shares—receives increased visibility. The algorithm favors posts that encourage meaningful interactions among users12.
Personalization: The algorithm customizes the news feed based on users’ past actions, interests, and connections, providing a tailored experience13.
Major Changes in 2025
Focus on Niche Content: The algorithm now emphasizes content relevance to specific niches, directing publications to audiences most likely to engage with them13.
Value of First-Degree Connections: Posts from first-degree connections are prioritized, fostering exchanges within users’ immediate networks and strengthening professional ties24.
Encouragement of Constructive Conversations: Content that stimulates deep discussions is favored over superficial interactions, promoting richer engagement13.
Recognition of Expertise: Contributions from recognized experts are valued more highly, highlighting the importance of sharing in-depth knowledge and professional experience14.
Factors Influencing Content Visibility
Quality of Content: High-quality, engaging posts that provide value are essential for visibility. Avoiding external links in posts is advised; instead, they should be placed in comments12.
Engagement Signals: The likelihood of engagement based on past interactions plays a crucial role in determining post ranking. Posts that receive quick engagement tend to rank higher26.
Network Interactions: Actively engaging with one’s network—through comments and shares—can enhance the visibility of both profiles and publications13.
Conclusion
In summary, the LinkedIn algorithm for 2025 emphasizes relevance, engagement, and personalization while prioritizing quality content from first-degree connections. Users are encouraged to create meaningful interactions and share expert knowledge to maximize their visibility on the platform.
For more detailed insights, you can refer to the following sources:
The LinkedIn 2025 algorithm prioritizes content from first-degree connections to enhance the relevance of users’ feeds. This change ensures that posts from immediate connections—such as colleagues, collaborators, and individuals users have interacted with—are displayed more prominently. Here are the key details:
Feed Prioritization: Posts from first-degree connections appear first in users’ feeds, as LinkedIn values content shared within direct professional networks over third-degree or viral content13.
Engagement and Relevance: The algorithm emphasizes meaningful interactions within first-degree networks, such as comments and shares, which foster deeper connections and discussions34.
Quality Connections: LinkedIn encourages users to maintain high-quality connections that contribute valuable professional content, further enhancing the feed’s relevance3.
This shift aligns with LinkedIn’s goal of creating a professional environment where users engage with trusted networks and expertise-driven content134.
Content that performs best with first-degree connections on LinkedIn typically focuses on fostering professional relationships, sharing valuable insights, and encouraging meaningful engagement. Here are the key types of content that resonate well:
Personalized Updates: Sharing personal achievements, career milestones, or updates about your professional journey helps strengthen relationships with immediate connections14.
Industry Insights: Posts that provide valuable information, such as trends, news, or expert analysis in your field, are highly engaging for first-degree connections interested in staying informed47.
Interactive Content: Asking questions, initiating discussions, or creating polls encourages direct engagement and interaction among your connections14.
Storytelling: Sharing relatable anecdotes or professional experiences that highlight lessons learned or challenges overcome can foster deeper connections and engagement7.
Collaborative Posts: Tagging first-degree connections in posts or mentioning them in comments helps boost visibility and interaction within your immediate network4.
These content types align with LinkedIn’s algorithm, which prioritizes posts that generate meaningful interactions among first-degree connections.
Ace Your ML Interview with 100+ Essential Questions Covering Algorithms, Models & Real-World Applications!
Covers key ML concepts thoroughly
This set of 200 questions ensures a strong understanding of fundamental and advanced machine learning concepts, from supervised learning to deep learning.
Focuses on algorithms and models
The questions emphasize important ML algorithms, optimization techniques, and various models like decision trees, neural networks, and ensemble learning.
Includes real-world ML applications
Practical applications of ML in industries such as healthcare, finance, and robotics are covered to help understand how ML is used in real scenarios.
Prepares for technical ML interviews
These questions are designed to help candidates tackle ML interviews by covering theoretical knowledge, coding challenges, and problem-solving techniques.
The Rise of AI-Driven IT Professionals: Why Upskilling is Essential for Legacy Experts
Introduction
The IT industry is experiencing a massive transformation, with artificial intelligence (AI) driving automation, decision-making, and data-driven insights. Employers are no longer looking for traditional IT professionals—they need AI-savvy experts who can manage end-to-end AI projects.
If you’re an IT professional with 10+ years of experience working with legacy systems, the time to upskill is now. Businesses demand specialists who can integrate AI into existing IT infrastructures, develop machine learning models, and automate processes.
Let’s explore the key roles employers are hiring for and why AI upskilling is a game-changer for legacy IT professionals.
Key Multi-Role AI Job Demands in IT
1. AI Integration Specialist
📌 Bridging AI with legacy IT systems ✅ Employers need experts who can seamlessly integrate AI into existing IT infrastructures without disrupting operations. 🔹 Required Skills: Cloud AI services, APIs, AI-powered automation, and data pipeline integration. 🔹 Why Upskill? To ensure AI-driven solutions work harmoniously with legacy infrastructure instead of requiring complete replacements.
2. Data Management & AI Engineer
📌 Transforming raw data into AI-ready assets ✅ Businesses depend on clean, structured data to power machine learning models and predictive analytics. 🔹 Required Skills: Data wrangling, big data technologies (Hadoop, Spark), and data preprocessing for AI. 🔹 Why Upskill? To prepare and manage high-quality data that feeds AI models for accurate insights.
3. Machine Learning Engineer
📌 Developing, training, and deploying AI models ✅ Companies expect IT professionals to build, train, and optimize machine learning models that drive automation. 🔹 Required Skills: Python, TensorFlow, PyTorch, MLOps, model deployment strategies. 🔹 Why Upskill? To take control of end-to-end AI projects rather than relying on data scientists alone.
4. AI Ethics & Compliance Officer
📌 Ensuring fairness, transparency, and legal compliance in AI ✅ AI solutions must be free from bias, secure, and ethically aligned with regulations. 🔹 Required Skills: AI ethics frameworks, bias detection techniques, compliance standards (GDPR, HIPAA). 🔹 Why Upskill? To develop responsible AI solutions that align with industry regulations and prevent bias-related risks.
5. AI-Powered Automation Architect
📌 Optimizing IT operations through AI-driven automation ✅ Organizations demand automated IT workflows, cybersecurity, and intelligent monitoring powered by AI. 🔹 Required Skills: AI-driven IT automation, DevOps, AIOps, predictive maintenance. 🔹 Why Upskill? To future-proof IT operations by implementing AI-driven optimizations for cost and efficiency.
Why Employers Prefer AI-Skilled IT Professionals
🚀 Future-Proofing IT Careers: AI adoption is skyrocketing, and IT professionals without AI expertise risk becoming obsolete.
💼 Higher Salary & Job Security: AI-integrated IT roles command premium salaries and have greater job stability compared to traditional IT jobs.
📊 End-to-End AI Expertise in Demand: Companies want professionals who can manage AI projects from data preparation to deployment—not just IT specialists handling individual tasks.
🌍 Global AI Adoption: Organizations across industries—including finance, healthcare, and manufacturing—are actively hiring AI-skilled IT experts to enhance operational efficiency and innovation.
Challenges Faced & Solved Through AI Upskilling
Legacy IT professionals face several challenges while transitioning to AI-driven roles. Here’s how upskilling resolves them:
1. Legacy System Integration for AI Implementation
✅ Challenge: Difficulty in integrating AI with outdated IT infrastructure. ✅ Solution: Learn modern API development and cloud migration to bridge the gap.
2. Data Management and Preprocessing for AI Readiness
✅ Challenge: Struggling to handle and structure unorganized data. ✅ Solution: Gain expertise in data engineering, preprocessing, and AI-driven analytics.
3. Machine Learning Model Development and Deployment
✅ Challenge: Limited knowledge of AI model development. ✅ Solution: Master ML algorithms, deep learning frameworks, and real-world deployment.
4. AI Ethics, Fairness, and Bias Mitigation
✅ Challenge: Bias in AI models due to poor data selection. ✅ Solution: Learn fairness principles, bias reduction techniques, and ethical AI implementation.
5. Automation and Optimization of IT Operations
✅ Challenge: Manual IT operations are time-consuming. ✅ Solution: Leverage AI-powered automation for cybersecurity, IT monitoring, and business intelligence.
Final Thoughts: The Path to Becoming a Transitioned AI Specialist
If you’ve spent a decade or more in IT, now is the perfect time to evolve your skill set and transition into AI.
🔹 Start Learning AI Technologies: Get hands-on experience with machine learning, AI automation, and data management. 🔹 Certifications & Courses: Enroll in AI-focused programs that cover AI ethics, cloud AI, and ML model deployment. 🔹 Real-World Projects: Work on AI-powered IT automation, intelligent monitoring, and AI-integrated cybersecurity.
By upskilling, you can secure high-demand AI roles, future-proof your career, and become a Transitioned AI Specialist—the professional every employer is looking for. 🚀
Are you ready to transform your career with AI? Start your AI upskilling journey today!
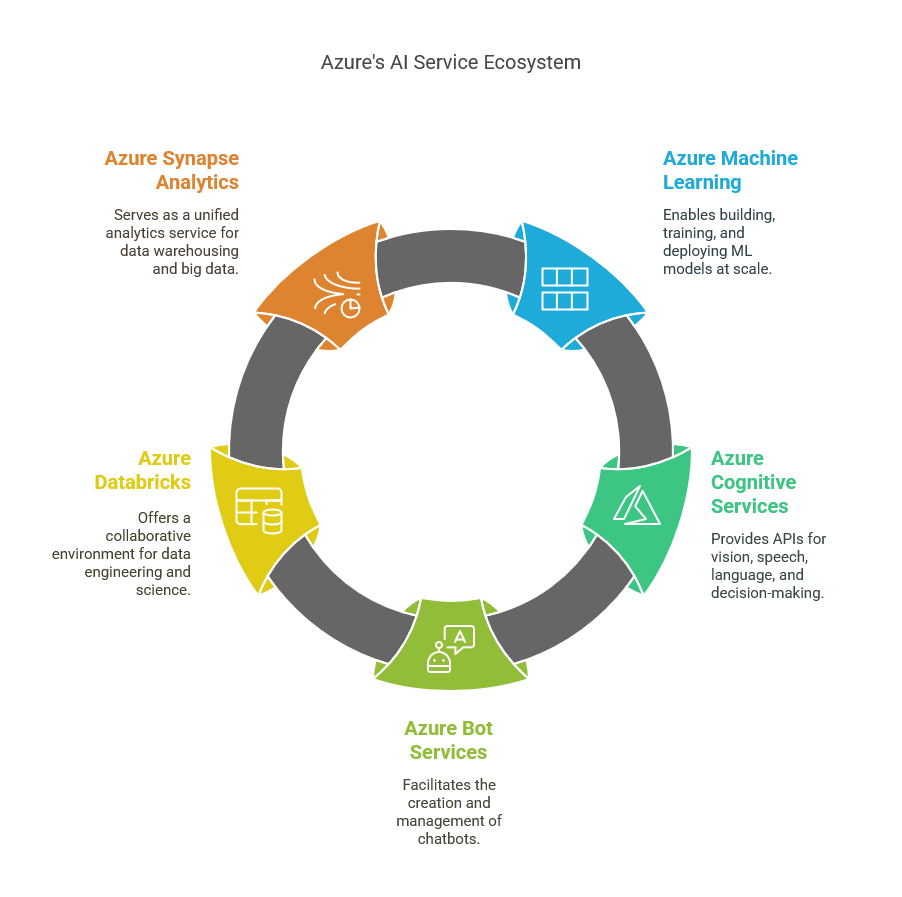
Azure provides a comprehensive suite of core services designed to facilitate the development, deployment, and management of artificial intelligence (AI) applications. Among these, Azure Machine Learning stands out as a powerful platform that enables IT professionals to build, train, and deploy machine learning models at scale. With features like automated machine learning, model interpretability, and robust collaboration tools, Azure Machine Learning caters to a wide range of use cases, from predictive analytics to natural language processing. This service empowers businesses to harness their data effectively and transform it into actionable insights, driving innovation and efficiency in their operations.
Another key service is Azure Cognitive Services, which offers a set of pre-built APIs that allow developers to integrate advanced AI capabilities into their applications without needing deep expertise in machine learning. These services encompass vision, speech, language, and decision-making functionalities, making it easier for organizations to enhance user experiences and automate processes. For instance, the Computer Vision API can analyze images and extract information, while the Speech Service enables real-time translation and transcription. By leveraging these cognitive services, IT professionals can quickly build intelligent applications that respond to user needs in real time.
Azure Bot Services is also essential for organizations looking to implement conversational AI solutions. This service allows developers to create and manage chatbots that can engage users across various channels, including websites, social media, and messaging platforms. The integration of natural language understanding through the Language Understanding (LUIS) service enhances the bots’ ability to comprehend user intents and respond appropriately. By utilizing Azure Bot Services, businesses can streamline customer interactions, reduce operational costs, and improve service delivery, ultimately leading to increased customer satisfaction.
In addition to these core services, Azure Databricks provides a collaborative environment for data engineering and data science. Built on Apache Spark, Databricks simplifies big data processing and enables teams to work together on AI projects seamlessly. By combining data storage, processing, and analytics capabilities, Databricks helps organizations unlock the full potential of their data, driving better decision-making and fostering innovation. IT professionals can leverage this platform to accelerate the development of AI models, ensuring they are built on accurate and up-to-date data.
Lastly, Azure Synapse Analytics serves as a unified analytics service that brings together big data and data warehousing. This service allows IT professionals to analyze vast amounts of data quickly and derive insights that can inform business strategies. With its integration of machine learning capabilities and support for real-time analytics, Azure Synapse Analytics empowers organizations to make data-driven decisions efficiently. Together, these core services of Azure create a robust ecosystem that enables IT professionals to architect AI solutions that drive business automation and enhance operational efficiency across various industries.
Data Management with Azure
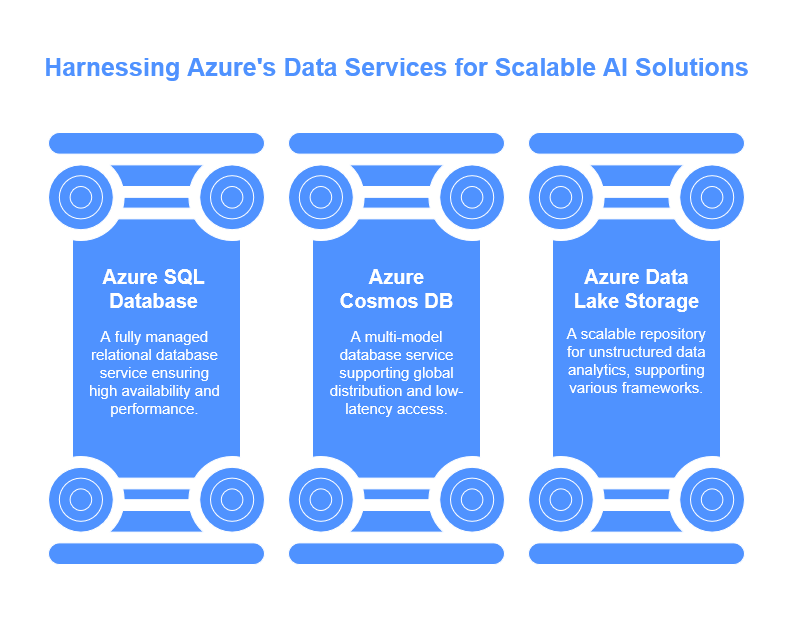
Data management is a cornerstone of effective business automation, and Azure provides a robust framework for handling data in a secure, efficient, and scalable manner. IT professionals engaged in architecting AI solutions can leverage Azure’s extensive database services, including Azure SQL Database, Cosmos DB, and Azure Data Lake Storage. Each service is designed to meet specific needs, from relational data management to unstructured data processing, enabling businesses to choose the right tool for their unique requirements. This versatility is crucial in an era where data-driven decision-making is paramount.
Azure SQL Database offers a fully managed relational database service that simplifies the management of data while maintaining high availability and performance. It supports advanced features such as automated backups, scaling, and built-in intelligence, allowing IT professionals to focus on application development rather than database maintenance. Moreover, its compatibility with SQL Server means that organizations can easily migrate existing applications to the cloud without significant rewrites. This seamless transition not only reduces downtime but also enhances the overall agility of business operations.
For applications requiring global distribution and low-latency access, Azure Cosmos DB stands out as a multi-model database service. It supports various data models, including key-value, document, and graph formats, making it an ideal choice for diverse workloads. With its ability to replicate data across multiple regions with ease, IT professionals can ensure that applications remain responsive regardless of user location. The automatic scaling feature of Cosmos DB further optimizes performance and cost, adapting to changing workloads without manual intervention, which is instrumental for businesses aiming to meet fluctuating demands.
Azure Data Lake Storage is another critical component of Azure’s data management ecosystem, particularly for organizations dealing with large volumes of unstructured data. It provides a scalable and secure repository for big data analytics, supporting various data processing frameworks like Apache Spark and Hadoop. This capability allows IT professionals to harness the full potential of their data, transforming raw information into actionable insights. By integrating data from multiple sources into a single platform, organizations can streamline their analytics processes, facilitating more informed decision-making and enhancing operational efficiency.
In conclusion, effective data management with Azure is integral to successfully architecting AI solutions for business automation. By utilizing Azure’s diverse array of data services, IT professionals can create a cohesive data strategy that aligns with organizational goals. Emphasizing scalability, security, and performance, Azure empowers businesses to not only manage their data effectively but also to leverage it as a strategic asset in their automation efforts. As organizations continue to navigate the complexities of digital transformation, a solid foundation in data management will be essential for driving innovation and achieving competitive advantage.
Security and Compliance in Azure
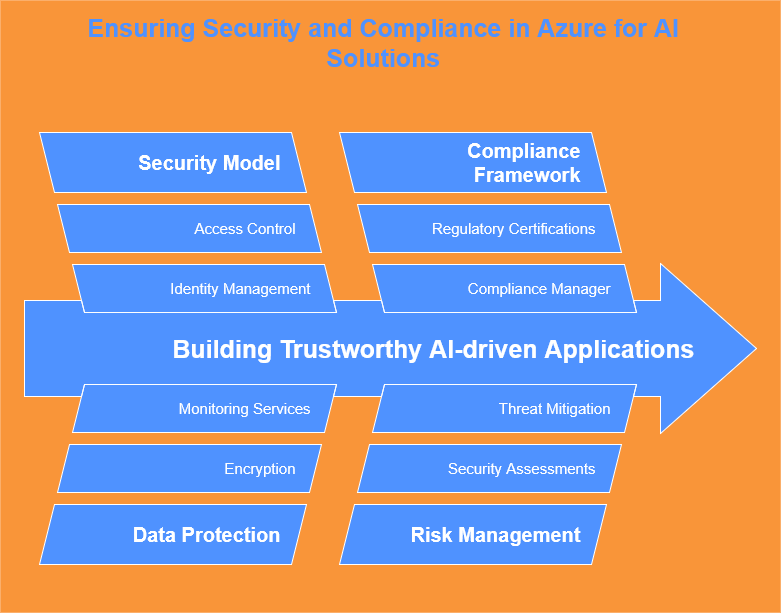
In the realm of cloud computing, security and compliance are paramount, especially when leveraging platforms like Azure to architect AI-driven business automation solutions. IT professionals must prioritize these elements to build trust and ensure the integrity of their applications. Azure provides a robust framework of security features, tools, and compliance certifications that can help organizations safeguard their data while adhering to regulatory requirements. Understanding these resources is essential for effectively managing risk and ensuring the resilience of business applications.
One of Azure’s most significant advantages is its comprehensive security model, which encompasses identity management, access control, data protection, and threat mitigation. Azure Active Directory plays a crucial role in managing user identities and access rights, enabling granular control over who can access which resources. This identity-centric approach not only enhances security but also simplifies compliance with regulations such as GDPR and HIPAA. IT professionals should leverage Azure’s security tools to implement multi-factor authentication and conditional access policies, ensuring that only authorized users can interact with sensitive business applications.
Data protection in Azure is facilitated by a variety of built-in encryption and monitoring services. Both data at rest and in transit can be secured through Azure’s encryption capabilities, which safeguard sensitive information against unauthorized access. Additionally, Azure Security Center provides continuous security assessments and recommendations, allowing organizations to maintain a proactive posture against potential threats. IT professionals must adopt these tools to ensure that their AI-driven applications not only meet security standards but also align with best practices in data governance and protection.
Compliance is a multifaceted challenge, particularly for organizations operating in regulated industries. Azure addresses this through a comprehensive compliance framework that includes a wide array of certifications and attestations. Azure’s Compliance Manager allows IT teams to assess their compliance posture and manage risks effectively. By staying informed about evolving regulations and leveraging Azure’s compliance tools, IT professionals can ensure that their business automation solutions not only meet legal requirements but are also aligned with industry standards, thereby fostering greater stakeholder confidence.
In conclusion, security and compliance in Azure are integral to the successful architecting of AI-powered business applications. By harnessing the platform’s security features, data protection mechanisms, and compliance tools, IT professionals can build resilient and trustworthy solutions. As the landscape of business automation continues to evolve, maintaining a strong focus on these aspects will be crucial for organizations looking to innovate while safeguarding their most valuable asset: data. Embracing Azure’s capabilities will empower IT teams to navigate the complex regulatory environment confidently and effectively.
Amazon Web Services (AWS) offers a comprehensive suite of core services specifically designed to facilitate artificial intelligence (AI) applications, enabling IT professionals to architect robust solutions for business automation. One of the foundational services is Amazon SageMaker, which provides a fully managed environment for building, training, and deploying machine learning models at scale. With SageMaker, professionals can leverage built-in algorithms and frameworks, reducing the complexity of model development. This service empowers organizations to integrate machine learning into their applications seamlessly, making it easier to derive insights and automate processes.
Another crucial service in the AWS AI landscape is AWS Lambda, which enables serverless computing that scales automatically in response to events. This is particularly beneficial for AI applications that require real-time data processing and analysis. IT professionals can configure Lambda functions to trigger in response to changes in data, such as new inputs from IoT devices or updates in databases, allowing for instantaneous reactions. By utilizing AWS Lambda, organizations can automate workflows efficiently, minimizing downtime and enhancing overall productivity.
Amazon Rekognition is another powerful AI service that allows for image and video analysis. IT professionals can incorporate this service into applications to enable features such as facial recognition, object detection, and scene analysis. By leveraging Rekognition, businesses can automate tasks that involve visual data, such as security monitoring, customer engagement through personalized experiences, and content moderation. The ability to analyze visual content at scale positions organizations to drive innovative solutions tailored to their specific needs.
AWS Comprehend, which provides natural language processing capabilities, is essential for businesses looking to automate text analysis and derive meaningful insights from large volumes of unstructured data. IT professionals can use Comprehend to build applications that understand sentiment, extract key phrases, and categorize text data. This service enhances decision-making processes by transforming raw text into actionable intelligence, allowing organizations to automate customer service interactions, improve marketing strategies, and streamline compliance processes.
Finally, AWS offers a range of AI services for data integration and orchestration, such as Amazon Kinesis and AWS Glue. These services enable IT professionals to collect, process, and prepare data for machine learning applications efficiently. With Kinesis, organizations can analyze streaming data in real-time, while Glue automates the data preparation and transformation processes needed for AI projects. By utilizing these core services, IT professionals can ensure that their AI initiatives are not only effective but also scalable, paving the way for enhanced business automation and innovation in their respective fields.
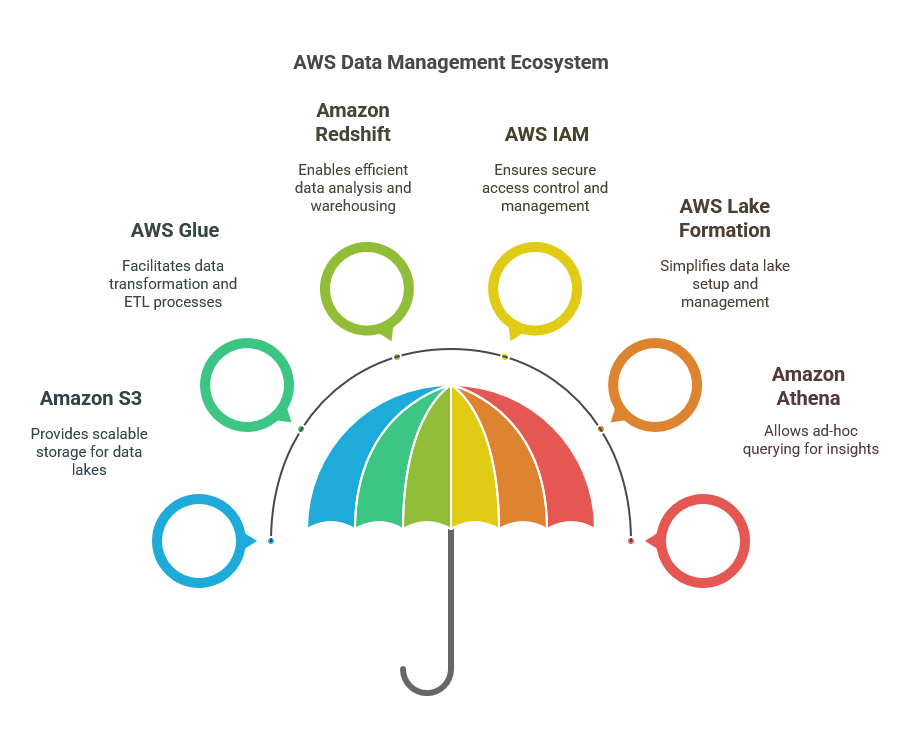
Data Management with AWS
Data management is a cornerstone of effective business automation, particularly when leveraging cloud services like AWS. In the realm of artificial intelligence, the way organizations handle data determines not only the efficiency of their operations but also their capability to extract meaningful insights. AWS offers a suite of tools and services that empower IT professionals to manage data seamlessly, ensuring that it is accessible, secure, and optimized for AI applications. By strategically utilizing these services, businesses can enhance their data workflows and foster innovation.
At the heart of AWS’s data management capabilities lies Amazon S3, a scalable object storage service that allows organizations to store and retrieve any amount of data from anywhere on the web. This flexibility enables IT professionals to implement robust data lakes, where vast amounts of unstructured data can be ingested and processed. By integrating machine learning models with data stored in S3, businesses can derive predictive analytics that drive decision-making. Furthermore, S3’s integration with other AWS services, such as AWS Glue and Amazon Redshift, enhances the ability to transform and analyze data efficiently, paving the way for more sophisticated AI applications.
Data security is a paramount concern for organizations, especially when handling sensitive information. AWS addresses this challenge through a combination of features and best practices that help IT professionals implement stringent security measures. Services like AWS Identity and Access Management (IAM) allow for fine-grained access control, ensuring that only authorized personnel can interact with specific datasets. Additionally, AWS provides encryption options for data at rest and in transit, helping to safeguard data integrity and confidentiality. By prioritizing security within their data management strategies, organizations can build trust with their stakeholders while maintaining compliance with industry regulations.
The integration of AWS with data analytics tools enhances the capability of businesses to derive insights from their data. Services such as Amazon Athena enable users to perform ad-hoc queries on data stored in S3 without the need for complex ETL processes. This not only accelerates the data analysis cycle but also empowers non-technical users to access insights, fostering a data-driven culture across the organization. Moreover, the use of AWS Lake Formation simplifies the process of setting up and managing data lakes, allowing IT professionals to focus on extracting value from data rather than wrestling with infrastructure challenges.
In conclusion, effective data management with AWS is integral to harnessing the power of AI for business automation. By leveraging AWS’s robust suite of tools, IT professionals can create a secure, scalable, and efficient data architecture that supports advanced analytics and machine learning initiatives. As the landscape of technology continues to evolve, embracing these data management practices will enable organizations to stay ahead of the curve, driving innovation and operational excellence in the age of AI.
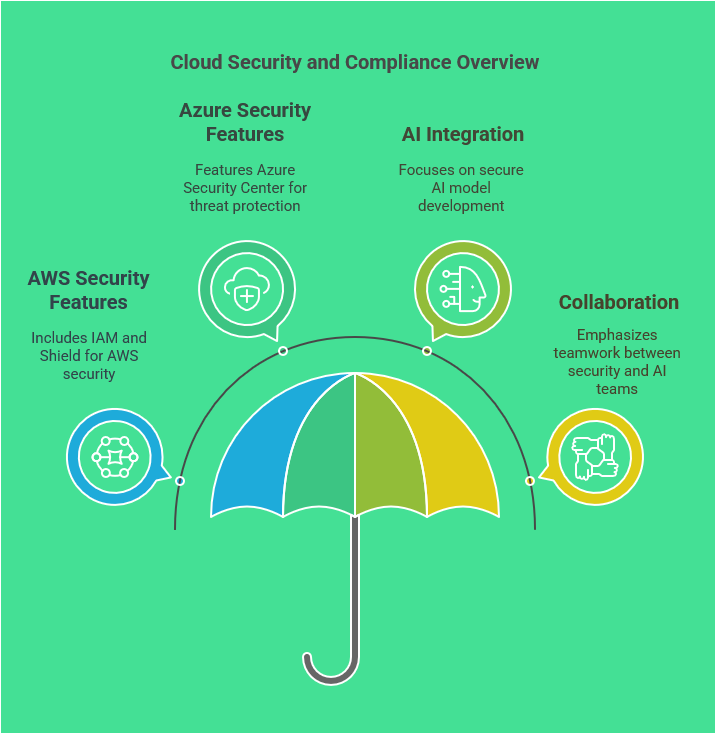
Security and Compliance in AWS
Security and compliance are critical considerations in any cloud architecture, especially when leveraging platforms like AWS and Azure for business automation. As IT professionals, understanding the security frameworks and compliance requirements of these cloud environments is essential for safeguarding sensitive data and maintaining regulatory adherence. Both AWS and Azure offer robust security features and compliance certifications that can help organizations protect their assets while automating processes through AI. By prioritizing security in the design and implementation phases, IT architects can build resilient systems that not only support business goals but also instill confidence in stakeholders.
AWS employs a shared responsibility model, which delineates security responsibilities between AWS and the customer. AWS is responsible for securing the infrastructure, while customers must secure their applications and data within the cloud. This model empowers organizations to implement security measures tailored to their specific needs. IT professionals should leverage AWS services such as Identity and Access Management (IAM), which allows for granular control over user permissions, and AWS Shield, which provides protection against DDoS attacks. Understanding these tools enables architects to create more secure environments that mitigate risks associated with cloud deployments.
Azure also emphasizes a shared responsibility model, along with a comprehensive set of compliance certifications that align with global standards, such as GDPR and HIPAA. IT architects must familiarize themselves with Azure’s security offerings, such as Azure Security Center, which provides unified security management and threat protection across hybrid cloud workloads. By utilizing Azure’s built-in security tools, organizations can enhance their security posture and ensure compliance with industry regulations. This proactive approach not only protects sensitive information but also streamlines the compliance process, allowing businesses to focus on innovation and automation.
Integrating AI into business applications further complicates the security landscape, as it introduces unique challenges and considerations. IT professionals need to adopt a security-first mindset when developing AI models that interact with sensitive data. This includes implementing data encryption both in transit and at rest, as well as ensuring that AI algorithms are robust against adversarial attacks. By leveraging AWS and Azure’s AI capabilities, such as Amazon SageMaker and Azure Machine Learning, organizations can build intelligent applications while maintaining a strong security framework that addresses potential vulnerabilities.
Collaboration between security teams and AI architects is vital to creating a holistic approach to security and compliance within cloud environments. Regular audits, vulnerability assessments, and compliance checks should be integral parts of the development lifecycle. By fostering a culture of security awareness and continuous improvement, IT professionals can ensure that their cloud architectures not only support automation through AI but also uphold the highest standards of security and compliance. This commitment to security will ultimately drive business success and foster trust among customers and stakeholders.
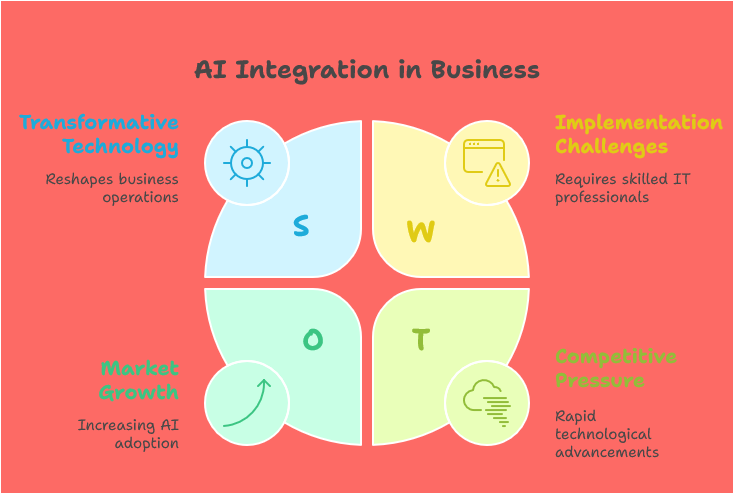
Artificial Intelligence (AI) has transitioned from a theoretical concept to a practical tool that is reshaping the business landscape. IT professionals are at the forefront of this transformation, tasked with integrating AI solutions into existing infrastructures. Understanding AI’s capabilities and its potential impact on business operations is essential for architects and developers alike. By leveraging AI technologies, organizations can optimize processes, enhance customer experiences, and make data-driven decisions that propel growth.
The integration of AI with cloud platforms like AWS and Azure offers unique advantages for businesses seeking automation. AWS provides a suite of AI services, such as Amazon SageMaker for building, training, and deploying machine learning models, while Azure features tools like Azure Machine Learning that facilitate the development of intelligent applications. These platforms not only simplify the implementation of AI but also ensure scalability and flexibility. IT professionals must familiarize themselves with these tools to effectively architect solutions that harness AI for business automation.
As businesses increasingly adopt AI, they are witnessing significant improvements in operational efficiency. AI-driven automation allows organizations to streamline workflows, reduce human error, and free up valuable resources for strategic initiatives. Tasks that were once labor-intensive can now be accomplished with precision and speed, leading to cost savings and increased productivity. IT professionals play a crucial role in identifying areas where AI can be applied, ensuring that the integration aligns with business objectives and delivers measurable results.
Moreover, AI enhances decision-making capabilities by providing insights derived from vast amounts of data. With advanced analytics and machine learning algorithms, businesses can uncover patterns and trends that inform strategic choices. IT professionals must focus on creating robust data architectures that support AI initiatives, enabling seamless data flow and real-time analysis. This data-driven approach empowers organizations to stay competitive and responsive to market changes, highlighting the importance of IT expertise in AI deployment.
In conclusion, understanding AI and its impact on business is vital for IT professionals involved in architecting solutions with AWS and Azure. The potential for AI to automate processes, improve efficiency, and enhance decision-making is immense. By embracing these technologies, IT architects can help businesses navigate the complexities of digital transformation, ultimately driving innovation and success in an increasingly automated world. As the landscape continues to evolve, ongoing education and adaptation will be key for professionals seeking to leverage AI effectively in their organizations.
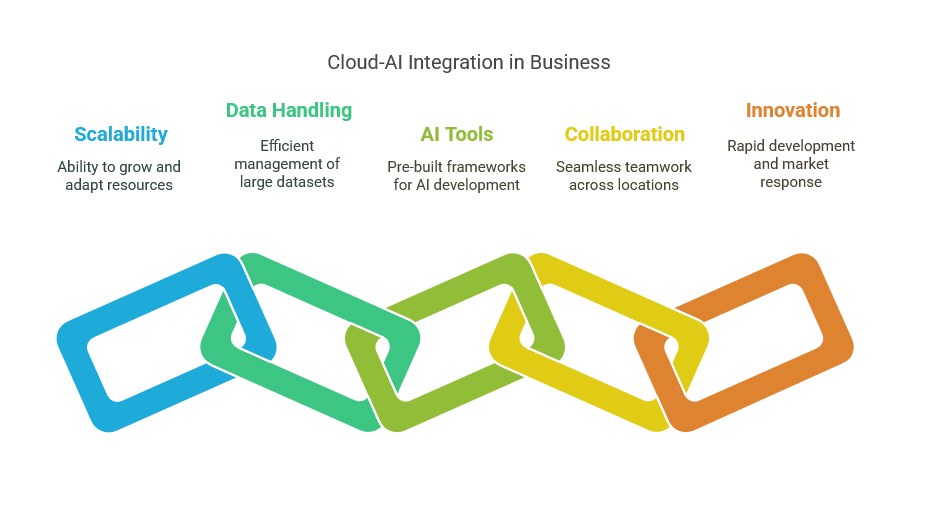
The Role of Cloud Computing in AI
The integration of cloud computing with artificial intelligence (AI) has transformed the landscape of business automation, enabling IT professionals to build scalable, efficient, and innovative solutions. Cloud platforms like AWS and Azure provide the necessary infrastructure and services that facilitate the deployment and management of AI applications. By leveraging cloud resources, organizations can access powerful computing capabilities, extensive storage options, and advanced AI tools without the need for substantial upfront investments in hardware and software. This flexibility allows businesses to innovate rapidly and respond to market demands effectively.
One of the key advantages of cloud computing in AI is its ability to handle massive datasets efficiently. AI algorithms thrive on vast amounts of data for training and learning. Cloud platforms offer the scalability required to store and process these datasets, enabling organizations to harness data from various sources, including IoT devices, customer interactions, and social media. This capability not only accelerates the development of AI models but also enhances their performance by allowing continuous learning and adaptation to new information. IT professionals can easily scale their data storage and compute resources, ensuring that their AI initiatives are not hindered by infrastructure limitations.
Moreover, cloud service providers offer a plethora of AI-specific tools and frameworks that simplify the development process for IT professionals. Services such as AWS SageMaker and Azure Machine Learning provide pre-built algorithms, development environments, and deployment options that allow teams to focus on building and refining their models rather than dealing with the underlying infrastructure. This ease of access to advanced technologies democratizes AI, enabling organizations of all sizes to implement AI-driven solutions that enhance business processes, improve customer experiences, and drive operational efficiencies.
The collaborative nature of cloud computing further enhances its role in AI development. With cloud platforms facilitating real-time collaboration among teams, IT professionals can work together seamlessly, regardless of their geographical locations. This collaboration is vital for AI projects, which often require cross-disciplinary expertise from data scientists, software engineers, and business analysts. By utilizing cloud-based tools, organizations can foster a culture of innovation, where ideas can be shared, tested, and iterated upon rapidly, leading to more effective AI applications that align closely with business objectives.
In summary, the synergy between cloud computing and AI is reshaping the way businesses approach automation and digital transformation. For IT professionals, understanding the capabilities and advantages of platforms like AWS and Azure is essential for architecting future-ready solutions. By leveraging cloud resources, organizations can build robust AI applications that not only enhance operational efficiency but also position them competitively in an increasingly data-driven marketplace. Embracing this technological convergence will empower IT professionals to lead their organizations into the future of intelligent business automation.
Overview of AWS and Azure Platforms
Amazon Web Services (AWS) and Microsoft Azure are two of the most prominent cloud computing platforms, playing a pivotal role in transforming the landscape of IT infrastructure and business applications. Both platforms provide a comprehensive suite of services that enable organizations to build, deploy, and manage applications in the cloud, making them indispensable for IT professionals looking to leverage artificial intelligence for business automation. AWS, with its extensive global infrastructure and vast array of services, empowers businesses to innovate rapidly while maintaining flexibility. Meanwhile, Azure offers seamless integration with Microsoft products, providing a familiar environment for enterprises already invested in Microsoft technologies.
AWS stands out for its mature ecosystem and extensive range of services, from computing power and storage to machine learning and data analytics. Its services like Amazon EC2, S3, and Lambda enable businesses to scale effortlessly according to demand. Additionally, AWS provides advanced AI services such as Amazon SageMaker, which simplifies the process of building and deploying machine learning models. This flexibility and scalability make AWS an ideal choice for organizations aiming to automate business processes and leverage AI capabilities to enhance operational efficiency and drive innovation.
On the other hand, Microsoft Azure has gained significant traction, particularly among enterprises looking for integrated solutions that align with existing Microsoft products. Azure’s offerings, such as Azure Machine Learning, Azure Functions, and Azure DevOps, allow IT professionals to create automated workflows that enhance collaboration and streamline processes. Azure’s commitment to hybrid cloud solutions also enables businesses to maintain a balance between on-premises infrastructure and cloud capabilities, facilitating a gradual transition to cloud-native applications while leveraging existing investments in technology.
The competitive nature of AWS and Azure has led to continuous innovation, with both platforms regularly introducing new features and services designed to meet evolving business needs. For IT professionals, understanding the strengths and weaknesses of each platform is crucial for making informed decisions about architecture and implementation. This understanding becomes even more vital when integrating AI capabilities into business applications, as both platforms offer unique tools and frameworks that can significantly enhance automation and data-driven decision-making.
In conclusion, both AWS and Azure offer robust frameworks for IT professionals to harness the power of AI in business automation. Their diverse range of services, coupled with their ongoing innovations, provides organizations with the tools needed to enhance productivity, optimize operations, and drive growth. As businesses continue to embrace digital transformation, a comprehensive understanding of these platforms will be essential for architects and developers in creating efficient, intelligent systems that can adapt to the ever-changing demands of the market.
Designing a machine learning (ML) model is a complex process that requires a multidisciplinary approach. Various roles come together to ensure the successful development, implementation, and maintenance of ML models. Each role has its own set of responsibilities and expertise, contributing to different stages of the ML model design process. In this blog, we will explore the standard roles involved in ML model design and their key activities.
1. Data Scientists
Data scientists are at the core of the ML model design process. Their responsibilities include:
Data Exploration and Analysis: Analyzing and interpreting complex data to uncover patterns, trends, and insights.
Feature Engineering: Creating new features or transforming existing ones to improve model performance.
Model Development: Experimenting with different ML algorithms and hyperparameters to develop predictive models.
Model Evaluation: Evaluating model performance using various metrics and techniques such as cross-validation and A/B testing.
2. Machine Learning Engineers
Machine learning engineers bridge the gap between data science and software engineering. Their key activities include:
Model Implementation: Implementing ML algorithms and models into production environments.
Optimization: Optimizing model performance and ensuring scalability and efficiency.
Deployment: Deploying ML models into production systems and integrating them with existing infrastructure.
Monitoring: Continuously monitoring model performance and addressing any issues or degradation.
3. Data Engineers
Data engineers play a crucial role in building and maintaining the data infrastructure required for ML model design. Their responsibilities include:
Data Collection: Designing and building data pipelines to collect, store, and process data from various sources.
Data Cleaning: Ensuring data quality, integrity, and availability for model training.
Data Preprocessing: Preprocessing and transforming raw data into a format suitable for analysis and model training.
Data Storage: Managing data storage solutions, such as databases and data lakes, to support large-scale data processing.
4. Software Developers
Software developers work closely with ML engineers and data scientists to implement and integrate ML models into applications. Their key activities include:
Application Development: Writing code and developing applications that utilize ML models.
Integration: Integrating ML-driven features and functionalities into existing systems.
Testing: Conducting unit tests and integration tests to ensure the reliability and performance of ML models.
Maintenance: Maintaining and updating applications to accommodate changes in ML models and data.
5. Business Analysts
Business analysts ensure that ML models address business needs and deliver value. Their responsibilities include:
Requirements Gathering: Identifying business needs and translating them into technical specifications for ML projects.
Stakeholder Communication: Communicating with stakeholders to understand their goals and expectations.
Performance Metrics: Defining success criteria and key performance indicators (KPIs) for ML models.
Evaluation: Evaluating the business impact and effectiveness of ML models.
6. Project Managers
Project managers oversee the end-to-end lifecycle of ML projects, ensuring they are delivered on time and within scope. Their key activities include:
Planning: Creating project plans, timelines, and resource allocations for ML projects.
Coordination: Coordinating with cross-functional teams, including data scientists, ML engineers, and stakeholders.
Risk Management: Identifying and mitigating risks that may impact project success.
Reporting: Providing regular updates and progress reports to stakeholders and executives.
7. UX/UI Designers
User experience (UX) and user interface (UI) designers focus on creating intuitive and user-friendly interfaces for ML-powered applications. Their responsibilities include:
Design: Designing interfaces that provide a seamless and engaging user experience.
Prototyping: Creating prototypes and wireframes to visualize the user interface.
Usability Testing: Conducting usability tests to gather feedback and make design improvements.
Collaboration: Working with developers to ensure that the final product aligns with design specifications.
8. Compliance and Ethics Officers
Compliance and ethics officers ensure that ML models adhere to legal, regulatory, and ethical standards. Their key activities include:
Regulatory Compliance: Ensuring that ML models comply with relevant laws and regulations.
Ethical Considerations: Addressing ethical issues related to bias, fairness, and transparency in ML models.
Data Privacy: Implementing measures to protect user data and ensure data privacy.
Audit and Review: Conducting audits and reviews to ensure ongoing compliance with ethical guidelines.
9. Domain Experts
Domain experts possess specialized knowledge in specific industries or fields, such as healthcare, finance, or retail. Their responsibilities include:
Expertise: Providing domain-specific knowledge and insights to guide ML model design.
Validation: Validating the relevance and accuracy of ML models in the context of the domain.
Collaboration: Collaborating with data scientists and ML engineers to ensure that models address domain-specific challenges and opportunities.
10. Stakeholders and Executives
Stakeholders and executives provide strategic direction and decision-making support for ML initiatives. Their key activities include:
Strategic Alignment: Aligning ML projects with organizational goals and objectives.
Decision-Making: Making informed decisions about resource allocation and project priorities.
Support: Providing support and guidance to ensure the success of ML projects.
Evaluation: Evaluating the overall impact and return on investment (ROI) of ML initiatives.
Conclusion
The design and development of ML models involve collaboration among various roles, each contributing their unique expertise and skills. Data scientists, ML engineers, data engineers, software developers, business analysts, project managers, UX/UI designers, compliance and ethics officers, domain experts, and stakeholders all play integral roles in the ML model design process. By working together, these roles ensure the successful implementation and maintenance of ML models that drive innovation and deliver business value.
The Role of Exploratory Data Analysis (EDA) in ML Model Design
In the ever-evolving world of machine learning (ML), the importance of a strong foundation cannot be overstated. One of the most critical steps in the ML model design process is Exploratory Data Analysis (EDA). EDA is a crucial phase that involves analyzing and visualizing data to understand its structure, patterns, and relationships before applying any machine learning algorithms. This blog will delve into the role of EDA in ML model design and how it contributes to building robust and accurate models.
What is Exploratory Data Analysis (EDA)?
EDA is the process of analyzing datasets to summarize their main characteristics, often with visual methods. It involves a variety of techniques to clean, transform, and visualize data. The primary goal of EDA is to uncover insights, identify patterns, detect anomalies, and test hypotheses, which ultimately guide the subsequent steps in the ML model design process.
The Importance of EDA in ML Model Design
1. Data Understanding and Discovery
EDA is the first step in understanding the data at hand. It helps data scientists and machine learning engineers grasp the underlying structure and distribution of the data. By exploring the data, they can identify trends, patterns, anomalies, and relationships that may impact the model’s performance. This initial exploration provides valuable insights and forms the basis for further analysis.
2. Data Cleaning and Preprocessing
High-quality data is essential for building accurate ML models. EDA helps in identifying and addressing issues such as missing values, outliers, and inconsistencies in the data. By visualizing data distributions and summary statistics, data scientists can make informed decisions about data cleaning and preprocessing techniques. This step ensures that the data is suitable for model training and improves the overall quality of the input data.
3. Feature Engineering
Feature engineering is the process of creating new features or transforming existing ones to improve model performance. EDA provides insights into the importance and relevance of different features in the dataset. By analyzing feature distributions, correlations, and interactions, data scientists can create meaningful features that capture the underlying patterns in the data. Effective feature engineering can significantly enhance the predictive power of the model.
4. Feature Selection
Not all features contribute equally to the model’s performance. EDA helps in identifying redundant or irrelevant features that do not add value to the model. By visualizing correlations and performing statistical tests, data scientists can select the most relevant features for model training. Feature selection helps in reducing the complexity of the model, improving its efficiency, and preventing overfitting.
5. Understanding Data Distribution
Understanding the distribution of the target variable and features is crucial for selecting appropriate machine learning algorithms. EDA allows data scientists to visualize data distributions and identify patterns such as skewness, normality, or other distributional characteristics. This information is essential for choosing algorithms that align with the data’s characteristics and for applying necessary transformations to normalize the data.
6. Identifying Relationships and Patterns
EDA helps in identifying relationships between features and the target variable. By visualizing scatter plots, heatmaps, and pair plots, data scientists can discover correlations and patterns that may impact the model’s performance. Understanding these relationships aids in making informed decisions during model design and helps in selecting features that have a significant impact on the target variable.
7. Validation of Assumptions
Machine learning algorithms often come with certain assumptions about the data. EDA is used to validate these assumptions and ensure that the data aligns with the requirements of the chosen algorithms. By exploring the data, data scientists can test hypotheses and check for violations of assumptions such as linearity, independence, and homoscedasticity. Validating these assumptions is crucial for selecting the right algorithms and techniques for the model.
8. Visualization and Communication
EDA provides powerful visualizations that help in communicating data insights and findings to stakeholders. Visualizations such as histograms, box plots, scatter plots, and correlation matrices make it easier to explain the data’s characteristics and justify decisions made during the model design process. Effective communication of EDA results ensures that all stakeholders have a clear understanding of the data and the rationale behind the chosen model design.
Tools and Techniques for EDA
EDA involves a variety of tools and techniques to analyze and visualize data. Some commonly used tools include:
Pandas: A Python library for data manipulation and analysis, providing data structures like DataFrames for handling structured data.
NumPy: A library for numerical computing in Python, offering support for arrays and mathematical functions.
Matplotlib: A plotting library for creating static, animated, and interactive visualizations in Python.
Seaborn: A Python visualization library built on Matplotlib, providing a high-level interface for drawing attractive and informative statistical graphics.
Plotly: A graphing library for interactive plots, supporting various chart types and customizations.
Jupyter Notebooks: An open-source web application that allows data scientists to create and share documents containing live code, equations, visualizations, and narrative text.
Conclusion
Exploratory Data Analysis (EDA) is a fundamental step in the ML model design process. By providing a comprehensive understanding of the data, EDA guides data scientists and machine learning engineers in making informed decisions about data preprocessing, feature engineering, model selection, and evaluation. Incorporating EDA into the ML workflow ensures that models are built on a solid foundation, leading to more accurate, reliable, and robust machine learning solutions.
In conclusion, EDA plays a pivotal role in uncovering insights, validating assumptions, and guiding the overall model design process. It empowers data scientists to make data-driven decisions, ultimately contributing to the success of machine learning projects. As the field of AI and ML continues to evolve, the importance of EDA in designing effective and reliable models remains paramount.
Learn from this blog and join the discussion in the video below:
The Complete Guide to Machine Learning Model Design, Development, and Deployment
Machine learning is transforming industries by leveraging data to create predictive models that drive decision-making and innovation. In this comprehensive guide, we’ll explore the key steps and tasks involved in designing, developing, and deploying a machine learning model. Whether you’re a data scientist, an engineer, or a business leader, this guide will provide you with a roadmap to navigate the intricate world of machine learning.
1. Data Preparation
Data is the foundation of any successful machine learning project. Proper data preparation ensures that your model is built on high-quality, consistent, and well-structured data.
Ingest Data
Collect raw data from multiple sources: Gather data from databases, APIs, web scraping, files (e.g., CSV, JSON), and other relevant sources. Ensure proper data access permissions and compliance with data privacy regulations.
Import data into a central storage location: Load the data into a data warehouse, data lake, or other centralized storage solutions using ETL (Extract, Transform, Load) tools.
Validate Data
Check for data quality, consistency, and integrity: Verify that the data meets predefined quality standards (e.g., accuracy, completeness, reliability). Identify and resolve inconsistencies, errors, and anomalies.
Verify data types and formats: Ensure that data columns have the correct data types (e.g., integers, floats, strings) and that date and time values are in the correct format.
Clean Data
Handle missing values: Identify missing values and choose appropriate methods to handle them, such as filling with mean/median values, forward/backward filling, or removing rows/columns with missing values.
Remove duplicates: Detect and remove duplicate rows to ensure data uniqueness.
Standardize data formats: Ensure consistency in data representation, such as uniform date formats and standardized text capitalization.
Standardise Data
Convert data into a structured and uniform format: Transform raw data into a tabular format suitable for analysis, ensuring all features have a consistent representation.
Normalize or scale features: Apply normalization (scaling values between 0 and 1) or standardization (scaling values to have a mean of 0 and standard deviation of 1) to numerical features.
Curate Data
Organize data for better feature engineering: Structure the data to facilitate easy feature extraction and analysis, creating derived columns or features based on domain knowledge.
Split data into training, validation, and test sets: Divide the dataset into subsets for training, validating, and testing the model, ensuring representative splits to avoid data leakage.
2. Feature Engineering
Feature engineering is the process of creating and selecting relevant features that will be used to train the machine learning model. Well-engineered features can significantly improve model performance.
Extract Features
Identify key patterns and signals from raw data: Analyze the data to uncover relevant patterns, trends, and relationships, using domain expertise to identify important features.
Create new features using domain knowledge: Generate new features based on understanding of the problem domain, such as creating time-based features from timestamps.
Select Features
Retain only the most relevant features: Use statistical methods and domain knowledge to select the most important features, removing redundant or irrelevant features that do not contribute to model performance.
Perform feature selection techniques: Utilize techniques such as correlation analysis, mutual information, and feature importance scores to evaluate feature relevance and select features based on their contribution to model performance.
3. Model Development
Model development involves selecting, training, and evaluating machine learning algorithms to create a predictive model that meets the desired objectives.
Identify Candidate Models
Explore various machine learning algorithms suited to the task: Research and select algorithms based on the nature of the problem (e.g., regression, classification, clustering), experimenting with different algorithms to identify the best candidates.
Compare algorithm performance on sample data: Evaluate the performance of candidate algorithms on a sample dataset, using performance metrics to compare and select the most promising algorithms.
Write Code
Implement and optimize training scripts: Write code to train the model using the selected algorithm, optimizing the training process for efficiency and performance.
Develop custom functions and utilities for model training: Create reusable functions and utilities to streamline the training process, implementing data preprocessing, feature extraction, and evaluation functions.
Train Models
Use curated data to train models: Train the model on the training dataset, monitoring the training process and adjusting parameters as needed.
Perform hyperparameter tuning: Optimize the model’s hyperparameters using techniques such as grid search, random search, or Bayesian optimization, evaluating the impact of different hyperparameter settings on model performance.
Validate & Evaluate Models
Assess model performance using key metrics: Calculate performance metrics to evaluate the model’s effectiveness, using appropriate metrics based on the problem type (e.g., classification, regression).
Validate models on validation and test sets: Test the model on the validation and test datasets to assess its generalization capability, identifying potential overfitting or underfitting issues.
4. Model Selection & Deployment
Once the model is trained and validated, it’s time to select the best model and deploy it to a production environment.
Select Best Model
Choose the highest-performing model aligned with business goals: Compare the performance of trained models and select the best one, ensuring it meets the desired business objectives and performance thresholds.
Package Model
Prepare the model for deployment with necessary dependencies: Bundle the model with its dependencies, ensuring it can be easily deployed in different environments.
Serialize the model: Save the trained model to disk in a format suitable for deployment.
Register Model
Track models in a central repository: Register the model in a central repository to maintain version control, documenting model details, including training data, hyperparameters, and performance metrics.
Containerise Model
Ensure model portability and scalability: Containerize the model using containerization technologies (e.g., Docker), ensuring it can be easily moved and scaled across different environments.
Use containerization technologies: Create Docker images for the model and its dependencies.
Deploy Model
Release the model into a production environment: Deploy the containerized model to a production environment (e.g., cloud platform, on-premises server), setting up deployment pipelines for continuous integration and continuous deployment (CI/CD).
Set up deployment pipelines: Automate the deployment process using CI/CD pipelines.
Serve Model
Expose the model via APIs: Create RESTful APIs or other interfaces to allow applications to interact with the model, implementing request handling and response formatting.
Implement request handling and response formatting: Ensure the model can handle incoming requests and provide accurate responses.
Inference Model
Enable real-time predictions: Set up the model to perform real-time predictions based on incoming data, monitoring inference performance and latency.
5. Continuous Monitoring & Improvement
The journey doesn’t end with deployment. Continuous monitoring and improvement ensure that the model remains accurate and relevant over time.
Monitor Model
Track model drift, latency, and performance: Continuously monitor the model’s performance to detect any changes or degradation, tracking metrics such as model drift, latency, and accuracy.
Set up alerts for significant performance degradation: Configure alerts to notify when the model’s performance drops below acceptable levels.
Retrain or Retire Model
Update models with new data or improved techniques: Periodically retrain the model with new data to ensure its accuracy and relevance, incorporating new techniques or algorithms to improve performance.
Phase out models that no longer meet performance standards: Identify and retire models that are no longer effective, replacing them with updated or new models.
In conclusion, the successful design, development, and deployment of a machine learning model require meticulous planning, execution, and continuous monitoring. By following these steps and tasks, you can create robust, scalable, and high-performing models that drive value and innovation for your organization.
Machine learning professionals often face challenges such as addressing gaps in their skill sets, demonstrating practical experience through real-world projects, and articulating complex technical concepts clearly during interviews.
They may also struggle with handling behavioral interview questions, showcasing their problem-solving abilities, and staying updated with the latest industry trends and technologies.
Effective preparation and continuous learning are essential to overcome these challenges and succeed in ML interviews.
A solution to these issues is shown in the provided PDF, which includes advice for both candidates and hiring managers.
Exploring the Role of a Microsoft Fabric Solution Architect: Real-World Case Studies
In the world of data analytics, the role of a Microsoft Fabric Solution Architect stands out as a pivotal position. This professional is responsible for designing and implementing data solutions using Microsoft Fabric, an enterprise-ready, end-to-end analytics platform. Let’s dive into the activities involved in this role and explore how three specific case studies can be applied to each of these activities.
Key Activities of a Microsoft Fabric Solution Architect
1. Designing Data Solutions
The first major responsibility of a Microsoft Fabric Solution Architect is designing data solutions. This involves analyzing business requirements and translating them into technical specifications. The architect must design data models, data flow diagrams, and the overall architecture to ensure solutions meet performance, scalability, and reliability requirements.
Case Study 1: Retail Company A retail company wanted to consolidate sales data from multiple stores to enable real-time sales analysis and inventory management. The solution architect designed a data warehouse that integrated sales data from various sources, providing a centralized platform for real-time analysis and decision-making.
Case Study 2: Healthcare Provider A healthcare provider aimed to integrate patient records, lab results, and treatment plans to improve patient care and operational efficiency. The solution architect created a lakehouse solution to integrate these data sources, enabling comprehensive patient data analysis.
Case Study 3: Financial Institution A financial institution needed to store and analyze transaction data to enhance fraud detection and compliance reporting. The solution architect developed a data lake that consolidated transaction data, improving the institution’s ability to detect fraudulent activities and comply with regulatory requirements.
2. Collaborating with Teams
Collaboration is key in the role of a solution architect. They work closely with data analysts, data engineers, and other stakeholders to gather requirements and translate them into technical specifications. Ensuring that solutions are optimized for performance and data accuracy is a crucial part of this activity.
Case Study 1: Retail Company The solution architect collaborated with data analysts to design a recommendation engine that personalized product suggestions for users, increasing sales and customer satisfaction.
Case Study 2: Healthcare Provider The solution architect worked with data engineers to implement a real-time data pipeline for monitoring network performance and identifying issues proactively. This collaboration ensured accurate and timely data for patient care analysis.
Case Study 3: Financial Institution The solution architect partnered with stakeholders to develop a claims processing system that reduced processing time and improved customer service, ensuring accurate data handling and compliance.
3. Implementing Best Practices
Following industry best practices is essential for designing and implementing efficient and maintainable solutions. The ‘medallion’ architecture pattern, for instance, is a popular best practice in data architecture.
Case Study 1: Retail Company The solution architect implemented the ‘medallion’ architecture to streamline data ingestion, transformation, and storage. This improved data quality and accessibility, enabling better sales analysis.
Case Study 2: Healthcare Provider The solution architect developed reusable data pipelines for tracking shipments and optimizing delivery routes, reducing operational costs and improving patient care logistics.
Case Study 3: Financial Institution The solution architect created a scalable data architecture for monitoring energy consumption and predicting maintenance needs, enhancing operational efficiency and fraud detection capabilities.
4. Ensuring Data Integrity and Security
Developing and maintaining data models, data flow diagrams, and other architectural documentation is a fundamental responsibility. Ensuring data integrity, security, and compliance with industry standards and regulations is vital for any data solution.
Case Study 1: Retail Company The solution architect designed a secure data warehouse for storing sensitive customer information, ensuring compliance with GDPR and other regulations. This protected customer data and ensured regulatory compliance.
Case Study 2: Healthcare Provider The solution architect implemented data governance policies to maintain the integrity and security of clinical trial data, ensuring regulatory compliance and accurate patient records.
Case Study 3: Financial Institution The solution architect developed a secure data lake for storing and analyzing public records, enhancing data transparency and accessibility while ensuring compliance with financial regulations.
5. Contributing to Knowledge Sharing
Knowledge sharing is an important activity for a solution architect. They share knowledge and experience gained from implementation projects with the broader team, build collateral for future implementations, and conduct training sessions and workshops.
Case Study 1: Retail Company The solution architect conducted workshops on best practices for data architecture, helping clients improve their data management strategies and increasing overall efficiency.
Case Study 2: Healthcare Provider The solution architect created documentation and training materials for new data engineers, accelerating their onboarding process and ensuring the team could effectively manage and utilize the integrated patient data.
Case Study 3: Financial Institution The solution architect developed a knowledge-sharing platform for faculty and staff to collaborate on data-driven research projects, fostering a culture of continuous learning and improvement.
6. Client-Facing Responsibilities
Engaging with clients to understand their needs and provide solutions that drive business value is a key part of the role. Solution architects present solutions, address client concerns, and ensure client satisfaction.
Case Study 1: Retail Company The solution architect worked with the client to design a customer loyalty program, increasing customer retention and sales. This involved understanding client needs and ensuring the solution delivered business value.
Case Study 2: Healthcare Provider The solution architect engaged with hospital administrators to develop a data-driven approach to patient care, improving treatment outcomes and client satisfaction.
Case Study 3: Financial Institution The solution architect collaborated with clients to implement a risk management system, enhancing their ability to identify and mitigate financial risks. This ensured the solution met client expectations and drove business value.
Conclusion
The role of a Microsoft Fabric Solution Architect is dynamic and multifaceted, requiring a combination of technical expertise, collaboration skills, and a deep understanding of data architecture. By exploring the activities involved in this role and applying real-world case studies, we can see how these professionals drive successful implementation and client satisfaction.
Whether designing data solutions, collaborating with teams, implementing best practices, ensuring data integrity and security, contributing to knowledge sharing, or engaging with clients, Microsoft Fabric Solution Architects play a critical role in transforming data into actionable insights that drive business value.
AI Agents: Evolution from Service-Oriented Applications to Intelligent Assistants
Artificial Intelligence (AI) has significantly reshaped the technological landscape, bringing forth a new era of intelligent agents. These AI agents, designed to perform tasks autonomously and interact with users in natural language, are a stark evolution from the traditional service-oriented applications (SOAs) of the past. This article explores how AI agents have revolutionized task management and compares this transformation to the earlier migration of service-oriented applications into intelligent assistants.
The Era of Service-Oriented Applications
Before the advent of AI agents, service-oriented applications played a pivotal role in business operations. These applications were designed to offer specific services through a network of interoperable components. Key characteristics of SOAs included:
Modularity: Services were divided into discrete units that could be reused across different applications.
Interoperability: These units could communicate with each other using standardized protocols.
Scalability: Services could be scaled up or down based on demand.
Loose Coupling: Components were designed to be independent, reducing dependencies and enhancing flexibility.
SOAs were instrumental in streamlining business processes, enabling organizations to deploy and manage services efficiently.
Transition to AI Agents
The transition from SOAs to AI agents marked a significant technological leap. AI agents are sophisticated programs capable of learning from data, making decisions, and performing tasks autonomously. Key differentiators between AI agents and traditional SOAs include:
Intelligence: AI agents are equipped with machine learning algorithms, enabling them to learn from experience and improve their performance over time.
Natural Language Processing (NLP): AI agents can understand and generate human language, facilitating more intuitive interactions with users.
Autonomy: AI agents can perform tasks without human intervention, making them highly efficient in managing repetitive and complex activities.
Context Awareness: These agents can understand the context of tasks and interactions, providing more relevant and personalized assistance.
Comparing SOAs and AI Agents
Task Automation
Service-Oriented Applications: SOAs primarily focused on automating specific services, such as processing transactions, managing inventory, or handling customer queries through predefined workflows.
AI Agents: AI agents take automation to the next level by not only performing predefined tasks but also learning from user interactions and data to optimize processes continuously. They can handle complex tasks that require understanding context, such as personalized customer support or predictive maintenance.
Interactivity and User Experience
Service-Oriented Applications: User interactions with SOAs were typically limited to predefined inputs and outputs through graphical user interfaces (GUIs). These interactions were often rigid and lacked personalization.
AI Agents: AI agents provide a more interactive and personalized user experience. Through NLP and machine learning, they can engage in natural language conversations, understand user preferences, and provide tailored responses. This enhances user satisfaction and engagement.
Integration and Flexibility
Service-Oriented Applications: SOAs were designed with interoperability in mind, allowing different services to communicate using standardized protocols. However, integrating new services often required significant effort and customization.
AI Agents: AI agents are designed to seamlessly integrate with various platforms and applications, leveraging APIs and other integration tools. They can dynamically adapt to different environments and requirements, offering greater flexibility and ease of deployment.
Decision-Making and Adaptability
Service-Oriented Applications: SOAs relied on predefined rules and logic to make decisions, limiting their ability to adapt to changing conditions or new information.
AI Agents: AI agents use advanced algorithms and data analytics to make informed decisions in real-time. They can adapt to new information, learn from outcomes, and continuously improve their performance, making them highly adaptable to changing business needs.
Real-world Implementations
Customer Support: Many organizations have transitioned from using SOAs for customer support to deploying AI agents. These agents can handle customer inquiries 24/7, provide personalized responses, and escalate complex issues to human agents when necessary.
IT Help Desk: Traditional IT help desks relied on SOAs to manage service requests and incidents. Today, AI agents can automate routine IT tasks, provide real-time support, and proactively identify and resolve issues before they impact users.
Sales and Marketing: AI agents have transformed sales and marketing by automating lead generation, personalizing marketing campaigns, and analyzing customer data to provide actionable insights. This is a significant advancement from the rule-based marketing automation tools used in SOAs.
Conclusion
The evolution from service-oriented applications to AI agents represents a paradigm shift in how organizations manage tasks and interact with users. AI agents offer unprecedented levels of intelligence, interactivity, and adaptability, making them indispensable tools in modern business operations. By leveraging the capabilities of AI agents, organizations can enhance productivity, improve user experiences, and stay competitive in an increasingly digital world.
AI Management Practice 11: Customizable Agents: Elevating Productivity in Microsoft 365
Customizable agents in Microsoft 365 enhance productivity by providing real-time assistance with tasks like managing emails, scheduling meetings, and generating reports. They improve communication through tools like Microsoft Teams and offer language support, breaking down barriers in global teams. Tailored to organizational needs, these agents adapt to workflows, automate routine tasks, and provide data-driven insights. Real-world implementations include employee IT self-help, real-time customer support, and SharePoint integration, demonstrating their transformative impact on modern workplaces.
AWS Services Demystified is designed to provide an in-depth understanding of Amazon Web Services (AWS) through practical, real-world examples and hands-on experience. The course is structured to guide you from foundational concepts to advanced applications, ensuring you gain a comprehensive understanding of AWS architectures and live implementations.
Module 1: Fundamentals of Cloud Computing and AWS
Introduction to Cloud Computing: Understand the basic concepts and characteristics of cloud computing.
AWS Core Services: Explore the primary services provided by AWS, including EC2, S3, and RDS.
Benefits of Cloud Computing: Learn about the advantages of using cloud services, such as scalability, flexibility, and cost-efficiency.
Module 2: Cloud Conversion Strategies
Migrating Legacy Systems: Step-by-step guide on transitioning from traditional IT systems to the cloud.
Challenges and Solutions: Identify potential obstacles during migration and strategies to overcome them.
Hybrid Cloud Solutions: Understand the integration of on-premises infrastructure with cloud services.
Module 3: AWS Infrastructure Security and Solutions
AWS Identity and Access Management (IAM): Learn to manage user permissions and access control.
Best Practices for Security: Implement security measures to protect your AWS infrastructure.
Virtual Private Cloud (VPC): Understand the importance and configuration of VPCs.
Module 4: Compliance and Advanced AWS Policies
AWS Compliance Standards: Explore the compliance requirements and how AWS meets them.
Virtual Desktops: Learn about AWS WorkSpaces and managing virtual desktops.
Advanced Policies: Delve into complex AWS policies and their applications.
Module 5: AWS Deployment Models Demystified
Deployment Models: Understand different AWS deployment models, including Elastic Beanstalk and CloudFormation.
Practical Scenarios: Explore real-world deployment scenarios and best practices.
Module 6: Storage Expertise with AWS S3
AWS S3 Features: Discover the capabilities of AWS S3, including data durability and availability.
Data Management: Learn about S3 versioning, lifecycle policies, and storage classes.
Practical Applications: Explore use cases and best practices for using AWS S3.
Module 7: Networking Mastery with AWS
Virtual Private Cloud (VPC): Gain a deep understanding of VPC components and configurations.
NAT Instances and Gateways: Learn about the role of NAT in AWS networking.
Internet Gateways: Configure and manage internet gateways for VPCs.
Module 8: Securing AWS Networks
Security Groups: Understand the function and configuration of security groups.
Network ACLs: Learn the difference between security groups and network ACLs.
Secure Communication: Implement secure communication practices between AWS resources.
Module 9: Connecting AWS VPCs
VPC Peering: Explore the concept and implementation of VPC peering.
AWS PrivateLink: Understand how PrivateLink ensures secure access to AWS services.
VPC Endpoints: Learn to set up and use VPC endpoints for private connectivity.
Module 10: AWS VPC Private EC2 Lab
Creating EC2 Instances: Step-by-step guide to creating and configuring private EC2 instances.
Subnetting: Gain hands-on experience with subnetting in AWS.
Private EC2 Lab: Set up a private EC2 test lab within a VPC.
Module 11: Efficient AWS CLI Usage
Introduction to AWS CLI: Learn the basics of AWS Command Line Interface (CLI).
Automation: Discover how to automate AWS operations using CLI.
Practical Scenarios: Explore real-world examples of efficient AWS CLI usage.
Module 12: Decoding AWS Networking
Networking Fundamentals: Understand VPG, CGW, and VPN in AWS networking.
VPN Setup: Step-by-step guide to setting up VPN connections.
AWS Direct Connect: Learn about Direct Connect and its applications.
Module 13: AWS RDS for Databases
Introduction to Amazon RDS: Explore the features and supported databases of RDS.
Database Optimization: Learn strategies for optimizing database performance.
Backup and Recovery: Understand backup and recovery options in RDS.
Module 14: AWS IAM: Identity and Access Management
IAM Roles and Users: Differentiate between IAM roles and users.
Multi-Factor Authentication (MFA): Implement MFA for enhanced security.
IAM Policies: Learn to create and manage IAM policies.
Module 15: AWS IAM and Active Directory (AD) Discussion
Integration with Active Directory: Understand how to integrate AWS IAM with AD.
AWS Managed AD: Explore the benefits and use cases of AWS Managed AD.
Mastering Machine Learning Interviews: Key Topics and Questions
Preparing for ML job interviews can be challenging, but with the right approach, you can master the process and ace your interviews. Here’s a list of 20 questions covering key topics in machine learning, along with how our course can help you prepare effectively.
Data Handling and Preprocessing
How can you handle imbalanced datasets in machine learning?
How do you effectively handle categorical variables in a dataset?
How can you handle missing values in a dataset?
Our course provides hands-on experience with techniques like SMOTE for balancing datasets, one-hot encoding for categorical variables, and methods for dealing with missing data.
Machine Learning Concepts and Algorithms
What is ensemble learning, and how can it improve model performance?
What are the differences between bagging and boosting?
How can transfer learning be applied?
Learn how to leverage ensemble learning techniques like bagging and boosting, and understand the principles of transfer learning through practical examples and case studies.
Model Evaluation and Selection
How do you choose the right evaluation metric for a machine learning problem?
How do you evaluate the performance of a clustering algorithm?
How do you handle hyperparameter tuning?
Our course teaches you how to select appropriate evaluation metrics, assess clustering algorithms, and perform hyperparameter tuning using grid search, random search, and Bayesian optimization.
Optimization and Regularization
Can you explain the difference between L1 and L2 regularization?
What techniques can reduce overfitting in machine learning models?
How do you choose the right activation function for a neural network?
Gain insights into regularization techniques, strategies for reducing overfitting, and selecting the optimal activation function for neural networks to enhance model performance.
Neural Networks and Deep Learning
What is the difference between a feedforward neural network and a recurrent neural network?
How do you evaluate the performance of a recommendation system?
How do you process large-scale data for machine learning?
Our course provides comprehensive knowledge of neural network architectures, evaluation techniques for recommendation systems, and methods for handling large-scale data processing.
Specific Techniques and Applications
What are common techniques for data augmentation, and why are they important?
What are some applications of natural language processing (NLP)?
How do you handle outliers in a dataset?
Learn about various data augmentation techniques, explore practical NLP applications, and discover ways to manage outliers effectively in your dataset.
General Knowledge and Comparisons
What is the difference between a generative and a discriminative model?
How can you compare logistic regression and linear regression?
Understand the distinctions between different machine learning models and algorithms, and learn how to apply them in real-world scenarios.
How the Course Can Help You Prepare
Our comprehensive digital course, “Ace Machine Learning Interviews: A Guide for Candidates and Hiring Managers,” is designed to help you master these topics and more. Here’s how it can assist you:
Technical Mastery: Deep dive into core ML concepts like handling imbalanced datasets, ensemble learning, and choosing evaluation metrics.
Behavioral Insights: Learn to effectively articulate experiences and technical knowledge using the STAR method. Master common behavioral questions.
Practical Assessments: Prepare for real-world scenarios and case studies that test your ML knowledge. Tips on analyzing case studies and performing practical assessments.
Resume Crafting: Create standout resumes highlighting your technical and soft skills, tailored for specific ML roles.
Interview Practice: Engage in mock interviews to refine responses, receive constructive feedback, and build confidence.
Role Clarity for Hiring Managers: Understand various ML roles and develop strategies to assess both technical and behavioral competencies.
Effective Interview Techniques: Design case studies and practical assessments tailored to your organization’s needs.
Building a Talent Pipeline: Leverage networking and job search strategies to attract top talent. Utilize online platforms and industry events.
Continuous Learning: Access a wealth of resources, including books, online courses, webinars, and expert guidance.
Whether you’re an aspiring ML professional looking to land your dream job or a hiring manager seeking to refine your interview process, our course provides the tools and insights needed to excel. By addressing both candidates and hiring managers, this course offers a holistic approach to mastering ML interviews.
Join us today and take the first step towards mastering the art of ML interviews.
How the Course Can Help You Prepare
Our comprehensive digital course, “Ace Machine Learning Interviews: A Guide for Candidates and Hiring Managers,” is designed to help you master these topics and more. Here’s how it can assist you:
Technical Mastery:
Deep dive into core ML concepts like handling imbalanced datasets, ensemble learning, and choosing evaluation metrics.
Hands-on experience with techniques such as data augmentation, L1 and L2 regularization, and feature scaling using tools like TensorFlow and PyTorch.
Behavioral Insights:
Learn to effectively articulate experiences and technical knowledge using the STAR method.
Master common behavioral questions to demonstrate skills in teamwork, problem-solving, and adaptability.
Practical Assessments:
Prepare for real-world scenarios and case studies that test your ML knowledge.
Tips on analyzing case studies and performing practical assessments, such as evaluating clustering algorithms and recommendation systems.
Resume Crafting:
Create standout resumes highlighting your technical and soft skills, tailored for specific ML roles.
Learn to present relevant projects, such as those involving NLP applications and handling missing data.
Interview Practice:
Engage in mock interviews to refine your responses, receive constructive feedback, and build confidence.
Role Clarity for Hiring Managers:
Understand various ML roles and develop strategies to assess both technical and behavioral competencies.
Effective Interview Techniques:
Design case studies and practical assessments tailored to your organization’s needs.
Assess candidate’s technical and behavioral competencies effectively.
Candidate Evaluation:
Evaluate resumes and identify key attributes that indicate strong candidates.
Conduct remote interviews efficiently, ensuring a smooth process.
Building a Talent Pipeline:
Leverage networking and job search strategies to attract top talent.
Utilize online platforms and industry events to expand professional networks.
Continuous Learning:
Access a wealth of resources, including books, online courses, webinars, and expert guidance.
Whether you’re an aspiring ML professional looking to land your dream job or a hiring manager seeking to refine your interview process, our course provides the tools and insights needed to excel.
By addressing both candidates and hiring managers, this course offers a holistic approach to mastering ML interviews. Join us today and take the first step towards mastering the art of ML interviews.
1. Who is this coaching program for? This program is designed for individuals who want to enhance their skills and transition into roles such as AWS Cloud/DevOps Engineer, AWS Automation Engineer, ML Engineer, ML Ops Engineer, Gen AI Developer, Gen AI Consultant, Prompt Engineering Expert, ML/Gen AI Solution Designer, ML to Gen AI Migration Expert, and AWS GenAIOps Role.
2. What are the prerequisites for joining this program? Participants should have a basic understanding of cloud services, programming, and IT infrastructure. Familiarity with AWS and Python will be beneficial but is not mandatory, as foundational concepts will be covered.
3. How is the coaching program structured? The program is divided into two main phases, each lasting 60 days. Phase 1 focuses on AWS Cloud, DevOps, Terraform, Python, Containers, and Clusters. Phase 2 delves into Machine Learning, ML Ops, and Generative AI. Each phase consists of multiple stages with specific learning objectives, hands-on activities, training sessions, review calls, and demos.
4. What support can I expect during the program? Participants will receive continuous training, guidance, mentoring, and review sessions throughout the program. There will be regular review calls to discuss progress, provide feedback, and address any challenges.
5. Can I take a break during the program? Yes, participants have the flexibility to take a 2-week break if needed. This allows for personal commitments or unforeseen circumstances without affecting overall program progression.
6. How will this program help me in my career? The program is designed to provide practical, hands-on experience with real-world tasks and demos. By completing the program, participants will enhance their profiles, demonstrating their expertise to potential employers and increasing their chances of securing competitive job offers.
7. What if I have additional questions or need more information? You can reach out to our support team [Whatspp # +91-8885504679] for any additional questions or clarifications. We are here to help you succeed in your career transition and professional growth for IT strategic Career Goals.
Watch the discussion video with a Roadmap for future participant from Singapore:
Benefits of Watching Mock Interview for AWS-Lex-Chatbot-Developer Role
In the ever-evolving tech industry, staying prepared for interviews is crucial to securing your dream job. Our latest mock interview with Siva Krishna for the AWS-Lex-Chatbot-Developer role offers valuable insights and benefits that can help you excel in your career. Here are some of the key advantages of watching this mock interview:
Real-World Experience
Gain insight into real-life interview scenarios and questions specific to the AWS Lex and Chatbot Developer role. This mock interview provides a realistic simulation of what you can expect during an actual interview, helping you familiarize yourself with the process.
Expert Feedback
Learn from detailed feedback and tips provided by experienced interviewers to improve your own interview performance. Our experts analyze each response and offer constructive advice to help you refine your answers and approach.
Skill Enhancement
Understand the key technical skills and best practices for designing and implementing chatbots using AWS Lex. This mock interview covers essential topics and techniques, ensuring you have the knowledge and skills needed to excel in the role.
Confidence Boost
Build your confidence by familiarizing yourself with common interview questions and effective responses. Practicing with mock interviews can help reduce anxiety and boost your self-assurance when facing real interviews.
Career Preparation
Get a comprehensive understanding of what to expect in a Cloud and DevOps interview, helping you prepare effectively for your dream job. This mock interview covers a range of relevant topics, ensuring you are well-prepared for any questions that may come your way.
By watching this mock interview, you’ll feel more prepared and confident for your upcoming interviews in the tech industry. Whether you’re a seasoned professional or just starting out, the insights and feedback provided in this video can be incredibly valuable.
🚀😊 Watch the mock interview here: Mock Interview with Siva Krishna for AWS-Lex-Chatbot-Developer Role: